![[Day #56 PyATS Series] Automating Pre/Post Config Change Checks (Brownfield) Using pyATS for Cisco [Python for Network Engineer]](https://networkjourney.com/wp-content/uploads/2025/08/Day-56-PyATS-Series-Automating-Pre_Post-Config-Change-Checks-Brownfield-Using-pyATS-for-Cisco.png)
Trainer Sagar Dhawan
- Posted on
[Day #56 PyATS Series] Automating Pre/Post Config Change Checks (Brownfield) Using pyATS for Cisco [Python for Network Engineer]
Table of Contents
Introduction on the key points
When working in a brownfield network, every configuration change carries risk. You must verify what is there now (pre-check), apply a change under controlled conditions, and verify what changed (post-check). Doing this manually is slow and error-prone — especially across dozens or hundreds of devices. With pyATS we can automate the entire pre/post validation pipeline:
- Snapshot device state (configs, routing, adjacency, counters) before the change.
- Run pre-check tests and gating assertions (interfaces up, critical routes present, BGP/OSPF neighbors green, STP root as expected).
- Apply change (manual operator or CI/CD pipeline) or orchestrate it via Ansible/pyATS.
- Re-snapshot and run post-checks and semantic diffs (configuration diffs plus operational validation).
- Produce both CLI-friendly and GUI-friendly outputs (JSON, HTML, Elasticsearch for Kibana).
- Provide clear rollback hints or automatic rollback options for failed gates.
This Article is a step-by-step masterclass you can copy into your lab and run immediately. We’ll treat brownfield realities (non-uniform CLI, different OS versions, partial features) and focus on safety: read-only pre/post checks, explicit gates, and optional manual approval.
Topology Overview
Use a small representative brownfield lab to practice; scale principles apply to large fleets.
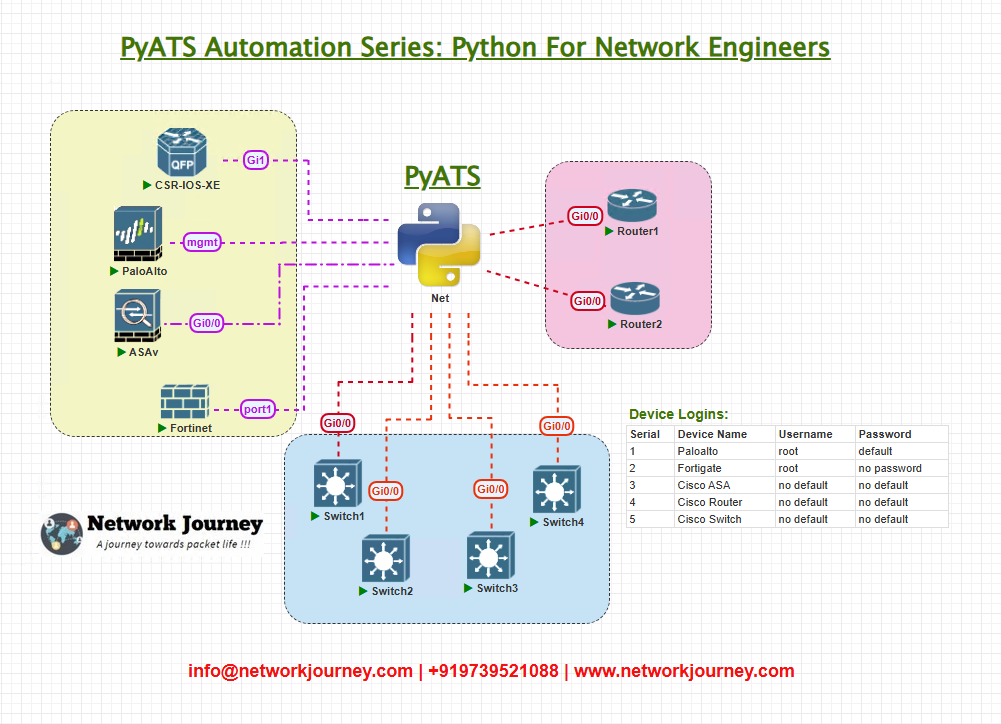
- Automation Host runs pyATS scripts and stores results to
results/. - Devices are reachable from management network and accept SSH.
- ELK/Kibana is optional for GUI validation: we’ll show how to push JSON results to ES indices for dashboards.
Topology & Communications
What we will collect (pre/post):
- Config:
show running-config(or vendor equivalent) - Critical operational commands:
- Interfaces:
show interfaces status,show ip interface brief - VLAN/STP:
show spanning-tree/show spanning-tree vlan <v> - Routing:
show ip route,show ip bgp summary,show ip ospf neighbor - ARP/ND:
show ip arp - CPU/Memory:
show processes cpu | include CPU - Logs relevant to change:
show logging | include %LINK-%|%SYS-%
- Interfaces:
- Test traffic checks:
- Ping from source to destinations (loopback reachability)
- Simple TCP connect checks if devices support it
How we talk to devices:
- SSH via pyATS/Genie device objects (
device.connect(),device.execute()), usingterminal length 0to avoid paging. - Use Genie parsers where available (
device.parse('show ip bgp summary')) and fall back to raw parsing when needed. - Store raw outputs and parsed JSON for auditing and GUI ingestion.
Validation points (gates):
- Pre-change gate (must pass): device reachable, interfaces up, critical BGP/OSPF neighbors present, no high CPU, recent config backup exists.
- Post-change gate (must pass): intended changes present in running config, no new neighbor loss, no major route regressions, no new STP topology changes, required reachability validated.
- If post-change gate fails, provide clearly the diff and suggest rollback steps or trigger an automated rollback workflow (optional).
Workflow Script
Below is a complete, production-style pyATS workflow script. It performs pre-check snapshotting, saves to disk, runs optional change step (placeholder), then performs post-checks and diffs, and writes a human-readable report plus a JSON document suitable for GUI ingestion.
Save as pyats_change_check.py.
#!/usr/bin/env python3
"""
pyats_change_check.py
Automated pre/post config change checks for brownfield networks using pyATS.
Usage:
python pyats_change_check.py --testbed testbed.yml --run-id change001
"""
import argparse, json, os, difflib, time
from datetime import datetime
from pathlib import Path
from genie.testbed import load
from pprint import pprint
OUTDIR = Path("results")
OUTDIR.mkdir(exist_ok=True)
# Configurable "checks" thresholds & test targets
PING_TARGETS = ["8.8.8.8"] # example: replace with internal targets
BGP_MIN_PEERS = 1
HIGH_CPU_THRESHOLD = 85.0 # percent
def now_ts():
return datetime.utcnow().isoformat() + "Z"
def save_raw(device_name, name, content):
d = OUTDIR / device_name
d.mkdir(parents=True, exist_ok=True)
fname = d / f"{name}.txt"
with open(fname, "w") as f:
f.write(content)
return str(fname)
def run_show_and_save(device, cmd, device_name, label):
"""Execute command and save raw output; return raw text."""
try:
out = device.execute(cmd)
path = save_raw(device_name, label, out)
return out, path
except Exception as e:
return None, str(e)
def collect_device_snapshot(device):
dname = device.name
snapshot = {"device": dname, "collected_at": now_ts(), "data": {}}
device.connect(log_stdout=False)
device.execute("terminal length 0")
# Collect key outputs (extend as required per vendor)
commands = {
"running_config": "show running-config",
"interfaces": "show interfaces status",
"ip_brief": "show ip interface brief",
"bgp_summary": "show ip bgp summary",
"ospf_neighbors": "show ip ospf neighbor",
"ip_route": "show ip route",
"arp": "show ip arp",
"logging": "show logging | tail 50",
"cpu": "show processes cpu | include CPU"
}
for label, cmd in commands.items():
out, path = run_show_and_save(device, cmd, dname, label)
snapshot["data"][label] = {"cmd": cmd, "raw_path": path, "raw": out}
device.disconnect()
return snapshot
def parse_bgp_summary(raw):
# simple parser: look for lines like "Neighbors: 2"
peers = None
if not raw:
return {"peers": None}
for line in raw.splitlines():
if "Neighbors" in line and ":" in line:
try:
peers = int(line.split(":")[1].strip())
except:
peers = None
# Genie would give a better structure if available; fallback simple parse
return {"peers": peers}
def evaluate_pre_checks(snapshot):
"""
Return list of issues found (empty if OK). Example checks:
- Device responded to commands (raw not None)
- CPU under threshold
- BGP peers >= BGP_MIN_PEERS (if BGP present)
"""
issues = []
dname = snapshot["device"]
data = snapshot["data"]
# basic reachability
for k,v in data.items():
if v["raw"] is None:
issues.append(f"{dname}: failed to collect {k}: {v['raw_path']}")
# CPU check
cpu_raw = data.get("cpu", {}).get("raw")
if cpu_raw:
# simple parse: find a percentage number in line
import re
m = re.search(r'(\d+\.\d+)%', cpu_raw)
if m:
cpu_val = float(m.group(1))
if cpu_val > HIGH_CPU_THRESHOLD:
issues.append(f"{dname}: high CPU {cpu_val}% > {HIGH_CPU_THRESHOLD}%")
# BGP check (simple)
bgp_raw = data.get("bgp_summary", {}).get("raw")
if bgp_raw:
bgp_info = parse_bgp_summary(bgp_raw)
peers = bgp_info.get("peers")
if peers is not None and peers < BGP_MIN_PEERS:
issues.append(f"{dname}: BGP peers low {peers} < {BGP_MIN_PEERS}")
return issues
def diff_configs(pre_cfg, post_cfg):
"""Produce unified diff string between two config strings."""
pre_lines = pre_cfg.splitlines(keepends=True)
post_lines = post_cfg.splitlines(keepends=True)
diff = difflib.unified_diff(pre_lines, post_lines, fromfile="pre", tofile="post")
return "".join(diff)
def load_text_path(path):
try:
with open(path) as f:
return f.read()
except:
return ""
def produce_report(run_id, pre_snapshots, post_snapshots, pre_issues, post_issues):
report = {
"run_id": run_id,
"started_at": pre_snapshots.get("_meta", {}).get("started_at"),
"completed_at": now_ts(),
"pre_issues": pre_issues,
"post_issues": post_issues,
"device_reports": []
}
for dev, pre in pre_snapshots.items():
if dev == "_meta":
continue
post = post_snapshots.get(dev)
dr = {"device": dev}
# read raw paths to diff configs
pre_cfg = load_text_path(pre["data"]["running_config"]["raw_path"])
post_cfg = load_text_path(post["data"]["running_config"]["raw_path"]) if post else ""
cfg_diff = diff_configs(pre_cfg, post_cfg) if pre_cfg and post_cfg else ""
dr["cfg_diff"] = cfg_diff
dr["pre_ok"] = len(pre_issues.get(dev, [])) == 0
dr["post_ok"] = len(post_issues.get(dev, [])) == 0
report["device_reports"].append(dr)
# save JSON and a human text report
out_json = OUTDIR / f"{run_id}_report.json"
with open(out_json, "w") as f:
json.dump(report, f, indent=2)
# also write human friendly summary
text = []
text.append(f"Change Run {run_id}")
text.append(f"Start: {report['started_at']} End: {report['completed_at']}")
text.append("Pre issues:")
for k,v in pre_issues.items():
text.append(f" {k}: {v}")
text.append("Post issues:")
for k,v in post_issues.items():
text.append(f" {k}: {v}")
# diffs
for d in report["device_reports"]:
text.append(f"=== Device {d['device']} ===")
text.append("Config diff:")
if d["cfg_diff"]:
text.append(d["cfg_diff"])
else:
text.append("<no diff or missing configs>")
out_txt = OUTDIR / f"{run_id}_report.txt"
with open(out_txt, "w") as f:
f.write("\n".join(text))
print("Report saved to:", out_json, out_txt)
return str(out_json), str(out_txt)
def main(testbed_file, run_id):
tb = load(testbed_file)
pre_snapshots = {"_meta": {"started_at": now_ts()}}
pre_issues = {}
# Pre-collection
for name, device in tb.devices.items():
print(f"[PRE] collecting {name}")
snap = collect_device_snapshot(device)
pre_snapshots[name] = snap
issues = evaluate_pre_checks(snap)
pre_issues[name] = issues
# If pre-issues contain fatal problems, we can optionally abort here
fatal = {k:v for k,v in pre_issues.items() if v}
print("Pre-issues summary:", {k: len(v) for k,v in pre_issues.items()})
# Placeholder: here is where change would be applied (manual or automated). We pause for operator.
input("PAUSE: Apply change now (or press Enter to continue after applying change)...")
time.sleep(2) # give devices time to converge after change
# Post collection
post_snapshots = {}
post_issues = {}
for name, device in tb.devices.items():
print(f"[POST] collecting {name}")
snap = collect_device_snapshot(device)
post_snapshots[name] = snap
issues = evaluate_pre_checks(snap) # same checks used as basic health checks
post_issues[name] = issues
# Produce report
out_json, out_txt = produce_report(run_id, pre_snapshots, post_snapshots, pre_issues, post_issues)
print("Done. See:", out_json)
# Exit code logic can be integrated with CI for gating
return 0
if __name__ == "__main__":
ap = argparse.ArgumentParser()
ap.add_argument("--testbed", required=True)
ap.add_argument("--run-id", required=True)
args = ap.parse_args()
main(args.testbed, args.run_id)
Notes:
- The script keeps raw outputs for auditing (
results/<device>/<label>.txt). evaluate_pre_checks()is a placeholder where you add your custom gating rules.- The script pauses for operator action between pre and post; you can replace that with an Ansible/pyATS change job trigger or CI step.
produce_report()writes JSON and a human-friendly text report (easy to email or push to ticket).
Explanation by Line
I’ll explain the key blocks so you can adapt them.
Top-level orchestration
main(testbed_file, run_id)— orchestrates pre-collection, pause, post-collection and report generation.run_iduniquely names the run for auditing.tb = load(testbed_file)loads testbed.yml; pyATS supports device-level credentials.
Snapshot collection
collect_device_snapshot(device)does:device.connect(log_stdout=False)– discreet connection.device.execute("terminal length 0")– avoids paging.- Runs a list of guarded commands and saves raw output to
results/<device>/. - Returns snapshot dict with raw content and raw file paths.
Why save raw outputs?
- Auditing: you must keep raw evidence of device behavior pre/post-change.
- Parsers/forensics: If something fails later, you have the original outputs.
Checks engine
evaluate_pre_checks(snapshot)is intentionally small and modular. Add checks here:- Interface up/down status and expected state.
- Critical loopback reachability (ping tests).
- BGP/OSPF neighbor counts or specific neighbor IPs.
- STP root identity unchanged (for switches).
- Security checks (ACL counters, unexpected deny logs).
- Return a list of human-readable issues to include in the report.
Diff and report
diff_configs(pre_cfg, post_cfg)produces unified diff between configs (human-friendly).produce_report()consolidates and stores JSON and text reports. The JSON can be pushed to ES for dashboards.
Integration points
- Replace the
input("PAUSE...")with:- A Jenkins pipeline step that triggers the change and continues on success.
- Ansible playbooks invoked from Python to push changes and then wait for convergence.
- A manual operator approval gateway.
Safety
- Script uses only read commands by default. If you add change orchestration capabilities, separate those modules and require explicit confirmation.
testbed.yml Example
testbed:
name: brownfield_lab
credentials:
default:
username: netops
password: NetOps123!
devices:
R1:
os: iosxe
type: router
connections:
cli:
protocol: ssh
ip: 10.0.1.11
Dist1:
os: iosxr
type: router
connections:
cli:
protocol: ssh
ip: 10.0.1.12
SW1:
os: nxos
type: switch
connections:
cli:
protocol: ssh
ip: 10.0.1.21
FW1:
os: fortios
type: firewall
connections:
cli:
protocol: ssh
ip: 10.0.1.31
Best practice: do not hardcode production credentials in files. Use environment variables or a secrets manager and load them into pyATS testbed programmatically.
Post-validation CLI (Real expected output)
Below are text-based screenshots you can paste into your blog. They show typical pre/post outputs and report excerpts.
A. Example show ip interface brief (pre)
R1# show ip interface brief Interface IP-Address OK? Method Status Protocol GigabitEthernet0/0 10.0.0.1 YES manual up up GigabitEthernet0/1 10.0.0.2 YES manual down down Loopback0 1.1.1.1 YES manual up up
B. Example show ip bgp summary (pre)
R1# show ip bgp summary BGP router identifier 1.1.1.1, local AS number 65000 BGP table version is 102 Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd 10.0.2.2 4 65001 12345 12350 102 0 0 2d02h 450
C. Example show running-config (pre snippet saved)
! Current configuration : 2345 bytes hostname R1 ! interface GigabitEthernet0/0 ip address 10.0.0.1 255.255.255.0 no shutdown ! router bgp 65000 neighbor 10.0.2.2 remote-as 65001 !
D. After applying change (post) — show running-config diff (report excerpt)
--- pre +++ post @@ interface GigabitEthernet0/0 ip address 10.0.0.1 255.255.255.0 no shutdown ! -router bgp 65000 - neighbor 10.0.2.2 remote-as 65001 +router bgp 65000 + neighbor 10.0.2.2 remote-as 65001 + neighbor 10.0.3.3 remote-as 65002
E. Post-check failure example: BGP neighbor dropped
[POST] Issues for R1: - BGP peers low: was 1 pre, now 0 - Critical prefix 172.16.0.0/16 missing from RIB Suggested action: rollback via config rollback <id> or re-enable neighbor 10.0.2.2
F. Report save logs
Report saved to: results/change001_report.json results/change001_report.txt
Practical checklist & quick recipes
Quick pre-change checklist to add to evaluate_pre_checks()
- Device reachable via SSH
show ip interface brief— all interfaces intended to be up areup/upshow ip routeincludes gateway / critical prefixesshow ip bgp summaryorshow ip ospf neighborshow expected neighborsshow loggingcontains no recent repeated flap / error spam- CPU < threshold, memory not saturated
- Latest config backup exists in Git (timestamped)
Quick post-change remediation flow
- If fail: immediately capture
show logging,show tech-supportto preserve evidence. - If automated rollback supported: apply rollback command and re-collect snapshots.
- If manual rollback: prepare PR with rollback diff and follow change-control.
FAQS
Q1. What are the essential pre-checks I must always run before a brownfield change?
A: At minimum:
- Device reachability (SSH/enable used by automation).
- Interface status for any impacted interfaces (up/up).
- Critical routing protocols and neighbors (BGP/OSPF adjacency).
- Baseline config backup exists (snapshot the current running-config).
- CPU/memory are within safe thresholds.
- Recent syslog doesn’t show repeated flaps or errors on affected devices.
These become the gating checks in evaluate_pre_checks().
Q2. How do you ensure the change window is safe and devices have converged before post-check?
A: Implement staged waits and active validation:
- After change, wait a conservative stabilization period (e.g., 30–120 seconds) and then re-run checks.
- For routing, wait for protocol-specific convergence events (BGP session UP & RIB entries present; OSPF neighbors FULL and LSDB exchange).
- Use active tests (pings/TCP connects) to validate actual reachability, not just control-plane state.
Q3. What if post-check detects partial regressions (some devices pass, others fail)?
A: Use clear remediation policy:
- For critical failures roll back immediately (if automated rollback is available).
- For limited failures, isolate impacted traffic using ACLs or route manipulation and open an incident.
- Always attach the diff and raw evidence to the ticket for the operator to triage.
Automation should provide recommended rollback commands (e.g., rollback 1 or git show <commit> with instructions).
Q4. How do I make diffs meaningful in brownfield (noisy configs)?
A: Normalization:
- Strip timestamps, CPU counters, ephemeral session IDs.
- Mask secrets.
- Canonicalize ordering of multi-line config blocks (where possible) — or use structured parsers (Genie) to extract logical differences rather than raw line diffs.
- Only report relevant sections (interfaces, routing protocols, ACLs) rather than raw full-config diffs if you want concise change summaries.
Q5. Can this be integrated into a CI/CD pipeline (Jenkins / GitLab / GitHub Actions)?
A: Absolutely. Typical flow:
- Commit candidate config to Git (or PR).
- Run automated pre-check job (this script) as a gating test.
- If pre-check passes, apply change via Ansible or a controlled playbook.
- Run post-check job.
- If post-check passes, merge PR; if fails, trigger rollback job and notify on-call.
Your pyATS job returns exit codes and produces artifacts that CI can inspect to pass/fail builds.
Q6. How do I manage different device OS variants in the same job?
A: Use device.os to select vendor-specific commands and parsers. Prefer Genie parsers where available; write small vendor-specific fallbacks when necessary. Organize collection commands per-OS in dictionaries and loop with a unified interface.
Q7. How do you reduce the blast radius of a failed change?
A: Techniques:
- Apply changes incrementally (canary devices first).
- Use maintenance windows and low-traffic times.
- Use temporary route-map or access-list staging for slow rollout.
- Implement automated rollback on severe failure detection with manual confirmation for non-critical failures.
- Maintain a precise inventory of impacted prefixes and services to quickly evaluate scope of failure.
Q8. How to show these results to stakeholders (GUI/dashboard)?
A: Push the JSON report to Elasticsearch index like change-checks-*. Build Kibana dashboards:
- Table: Latest runs with pass/fail per device.
- Time series: Number of failed checks over time.
- Device detail: config diffs and raw evidence links.
For lightweight setups, generate an HTML report (simple Jinja2 template) and host it on automation server, or email report.txt as part of the change ticket.
YouTube Link
Watch the Complete Python for Network Engineer: Automating pre/post config change checks (brownfield) Using pyATS for Cisco [Python for Network Engineer] Lab Demo & Explanation on our channel:
Join Our Training
If you want to go from ready-made scripts to production-grade change orchestration, with hands-on instructor feedback, join Trainer Sagar Dhawan’s 3-month instructor-led program covering Python, Ansible, APIs and Cisco DevNet—designed specifically for practicing network engineers. The course walks you through building pipelines like this one, integrating CI/CD, secure secrets management, and GUI dashboards that operators use daily.
Learn more & enroll: https://course.networkjourney.com/python-ansible-api-cisco-devnet-for-network-engineers/
Take the next step in your journey as a Python for Network Engineer — build automation that reduces outages and gives you confidence to change production networks.
Enroll Now & Future‑Proof Your Career
Email: info@networkjourney.com
WhatsApp / Call: +91 97395 21088
![[Day #36 Pyats Series] Port-channel consistency validation across platforms using pyATS for Cisco [Python for Network Engineer]](https://networkjourney.com/wp-content/uploads/2025/08/Port-channel-consistency-validation-across-platforms-using-pyATS-for-Cisco.png)
![[Day#1c PyATS Series] Why pyATS? Why not just stick to Netmiko / NAPALM / Paramiko which are easier? [Python for Network Engineer]](https://networkjourney.com/wp-content/uploads/2025/07/Day1c-PyATS-Series-Why-pyATS-Why-not-just-stick-to-Netmiko-NAPALM-Paramiko-which-are-easier-Python-for-Network-Engineer.png)
![Git and GitHub for Network Engineers – Version Control Made Easy [CCNP ENTERPRISE]_networkjourney](https://networkjourney.com/wp-content/uploads/2025/07/Git-and-GitHub-for-Network-Engineers-–-Version-Control-Made-Easy-1.png)