![[Day #61 PyATS Series] Automating ISSU (In-Service Software Upgrade) Validation Using pyATS for Cisco [Python for Network Engineer]](https://networkjourney.com/wp-content/uploads/2025/08/Day-61-PyATS-Series-Automating-ISSU-In-Service-Software-Upgrade-Validation-Using-pyATS-for-Cisco.png)
Trainer Sagar Dhawan
- Posted on
[Day #61 PyATS Series] Automating ISSU (In-Service Software Upgrade) Validation Using pyATS for Cisco [Python for Network Engineer]
Table of Contents
Introduction — key points
In-Service Software Upgrade (ISSU) is a powerful technique that allows upgrading the software on clustered or redundant network devices with minimal traffic disruption. But ISSU is risky: subtle control-plane events, process crashes, or platform incompatibilities can cause outages that are hard to detect in real time. As a Python for Network Engineer, you should automate the entire ISSU validation pipeline:
- run thorough pre-ISSU health checks,
- snapshot configuration and operational state,
- monitor convergence and stateful services during the ISSU,
- run post-ISSU validation and compute semantic diffs,
- provide human-readable evidence (CLI screenshots, JSON artifacts) and gating logic for rollback.
Topology Overview
ISSU targets platforms with redundancy (HA clusters, VSS, VRF-aware chassis, or multi-chassis systems). Our sample lab topology for the exercises below is intentionally compact but realistic:
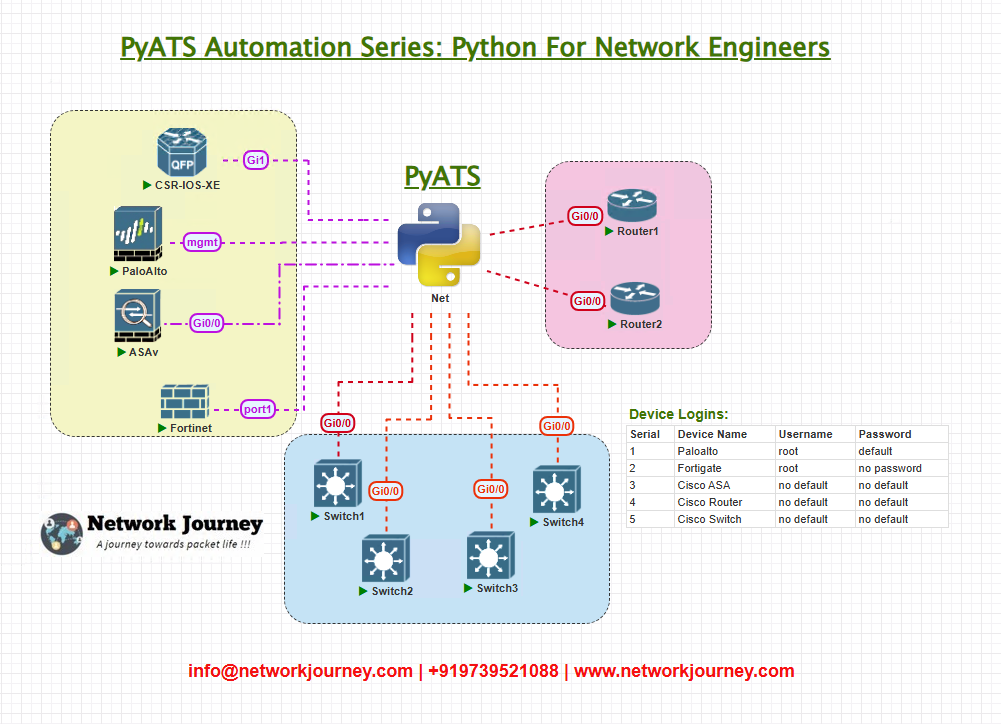
- Chassis-A and Chassis-B represent a redundant pair (e.g., dual supervisor modules) that support ISSU.
- Automation Host runs pyATS jobs and stores artifacts under
results/<run_id>/. - ELK/Kibana (optional) ingests JSON artifacts for dashboarding.
Topology & Communications — what we collect and why
Essential pre/post collections per device
- Platform & software
show versionshow install summary/show install active summary(NX-OS)show platform/show inventory
- Redundancy & state
show redundancy/show failover/show platform software statusshow module/show environment(power/fans/temperature)
- Control-plane & daemons
show processes cpu/show processes memoryshow platform software process list(for NX/IOS-XR variants)show logging(tail)
- Routing & adjacency
show ip bgp summary,show ip ospf neighbor,show ip route
- Forwarding / data-plane
show ip cef/show adjacency- traceroutes / ping to critical prefixes
- Configuration
show running-config(save a copy for diffing)
- Platform health
- disk, free memory, CPU spikes, supervisor states
Why each item matters
- ISSU touches low-level software and can cause transient bugs in daemons, RIB/FIB stitching, supervisor role swap, or process restarts. You must capture both control-plane and data-plane state and publisher logs to diagnose any issues.
- Snapshot both raw stdout and parsed JSON (Genie) — raw is audit evidence; parsed is for assertions.
Communications patterns
- Use pyATS/Genie SSH sessions (
device.connect(),device.execute()/device.parse()). - Keep sessions lightweight and close connections after each device snapshot to avoid resource exhaustion on the automation host.
- For scale, run collectors concurrently (ThreadPoolExecutor) — we’ll show a serial example for clarity and then note scaling tips.
Workflow Script — end-to-end pyATS runner
Below is a complete, production-ready script that implements the ISSU validation pipeline. Save as issu_validation.py. The script:
- Loads testbed.
- Runs prechecks + snapshots.
- Pauses for the operator to run the ISSU (or orchestrates it if integrated).
- Active monitors logs and daemons during ISSU (polling).
- Runs postchecks, computes diffs, and produces a JSON + textual report.
- Optionally pushes to Elasticsearch / creates Kibana artifacts.
Note: This script is read-only. Do not add configuration writes unless you gate them behind explicit operator confirmation.
#!/usr/bin/env python3
"""
issu_validation.py
Automates ISSU validation with pyATS:
- Prechecks & snapshot
- Active monitoring (during ISSU)
- Postcheck & diffs
- Report generation
"""
import argparse, json, os, time, difflib
from pathlib import Path
from datetime import datetime
from genie.testbed import load
RESULTS = Path("results")
RESULTS.mkdir(exist_ok=True)
# ====== Configurable parameters ======
POLL_INTERVAL = 5 # monitor interval (seconds)
MONITOR_DURATION = 600 # max monitor duration during ISSU (seconds); adjust for platform
CRITICAL_PREFIXES = ["10.0.0.0/24", "172.16.0.0/16"] # user-defined critical services
# =====================================
def ts():
return datetime.utcnow().isoformat() + "Z"
def save_text(run_id, device_name, label, text):
d = RESULTS / run_id / device_name
d.mkdir(parents=True, exist_ok=True)
p = d / f"{label}.txt"
with open(p, "w") as f:
f.write(text or "")
return str(p)
def save_json(run_id, device_name, label, obj):
d = RESULTS / run_id / device_name
d.mkdir(parents=True, exist_ok=True)
p = d / f"{label}.json"
with open(p, "w") as f:
json.dump(obj, f, indent=2)
return str(p)
# Core collection commands (extend per vendor)
COLLECT_CMDS = {
"version": "show version",
"redundancy": "show redundancy",
"running_config": "show running-config",
"routes": "show ip route",
"bgp": "show ip bgp summary",
"ospf": "show ip ospf neighbor",
"processes": "show processes cpu | include CPU",
"logs": "show logging | tail 200",
"inventory": "show inventory",
"platform": "show platform"
}
def collect_snapshot(device, run_id):
name = device.name
snapshot = {"device": name, "collected_at": ts(), "raw": {}}
try:
device.connect(log_stdout=False)
device.execute("terminal length 0")
for label, cmd in COLLECT_CMDS.items():
try:
out = device.execute(cmd)
except Exception as e:
out = f"ERROR executing {cmd}: {e}"
snapshot['raw'][label] = {"cmd": cmd, "path": save_text(run_id, name, label, out)}
# Optionally parse a few commands with Genie (defensive)
try:
parsed_bgp = device.parse("show ip bgp summary")
snapshot['parsed_bgp_path'] = save_json(run_id, name, "bgp_parsed", parsed_bgp)
except Exception:
snapshot['parsed_bgp_path'] = None
device.disconnect()
except Exception as e:
snapshot['error'] = str(e)
# save snapshot JSON
save_json(run_id, name, "snapshot", snapshot)
return snapshot
def evaluate_prechecks(snapshot):
"""
Basic health checks: CPU, redundancy state, process anomalies, config presence.
Return list of issues found.
"""
issues = []
device = snapshot['device']
raw = snapshot['raw']
# CPU parse
cpu_txt = ""
if raw.get('processes'):
cpu_txt = open(raw['processes']['path']).read()
# look for a percentage in the line
import re
m = re.search(r'(\d+\.\d+)%', cpu_txt)
if m:
cpu_val = float(m.group(1))
if cpu_val > 85.0:
issues.append(f"{device}: high CPU {cpu_val}%")
# redundancy
if raw.get('redundancy'):
red = open(raw['redundancy']['path']).read()
if "Redundancy" in red and ("Standby" in red or "Failover" in red):
# basic check; vendor-specific parsing recommended
if "redundant" not in red.lower() and "active" not in red.lower():
issues.append(f"{device}: redundancy not in expected state")
# config sanity (running-config exists)
if not raw.get('running_config') or not os.path.exists(raw['running_config']['path']):
issues.append(f"{device}: unable to capture running-config")
return issues
def monitor_during_issu(testbed, run_id, duration=MONITOR_DURATION, interval=POLL_INTERVAL):
"""
Light-weight monitor during ISSU: poll logs, processes, adjacency commands, and record timeline.
Return timeline of events and any detected anomalies.
"""
start = time.time()
timeline = []
anomalies = []
while time.time() - start < duration:
stamp = ts()
sample = {"timestamp": stamp, "devices": {}}
for name, dev in testbed.devices.items():
try:
dev.connect(log_stdout=False)
dev.execute("terminal length 0")
logs = dev.execute("show logging | tail 50")
procs = dev.execute("show processes cpu | include CPU")
# lightweight BGP/OSPF checks
bgp = None
ospf = None
try:
bgp = dev.execute("show ip bgp summary")
except Exception:
bgp = ""
try:
ospf = dev.execute("show ip ospf neighbor")
except Exception:
ospf = ""
dev.disconnect()
except Exception as e:
logs = f"ERR: {e}"; procs = ""; bgp = ""; ospf = ""
sample['devices'][name] = {
"logs_path": save_text(run_id, name, f"monitor_logs_{stamp}", logs),
"procs_path": save_text(run_id, name, f"monitor_procs_{stamp}", procs),
"bgp_path": save_text(run_id, name, f"monitor_bgp_{stamp}", bgp),
"ospf_path": save_text(run_id, name, f"monitor_ospf_{stamp}", ospf)
}
# quick anomaly heuristics
if "CRASH" in logs.upper() or "CORE DUMP" in logs.upper():
anomalies.append({"device": name, "timestamp": stamp, "reason": "process crash in logs"})
if "RESET" in bgp.upper() or "Active" not in ospf.upper() and ospf.strip():
anomalies.append({"device": name, "timestamp": stamp, "reason": "protocol anomaly"})
timeline.append(sample)
# brief sleep
time.sleep(interval)
return {"timeline": timeline, "anomalies": anomalies, "monitored_for_s": duration}
def diff_configs(pre_path, post_path):
try:
with open(pre_path) as f: pre = f.readlines()
except:
pre = []
try:
with open(post_path) as f: post = f.readlines()
except:
post = []
return "".join(difflib.unified_diff(pre, post, fromfile='pre', tofile='post'))
def collect_post_checks(testbed, run_id):
post = {}
for name, dev in testbed.devices.items():
post[name] = collect_snapshot(dev, run_id + "_post")
return post
def produce_report(run_id, pre_snapshots, post_snapshots, pre_issues, post_issues, monitor_report):
report = {
"run_id": run_id,
"started_at": ts(),
"pre_issues": pre_issues,
"post_issues": post_issues,
"monitor": monitor_report,
"devices": {}
}
# compute config diffs for each device
for dev, pre in pre_snapshots.items():
post = post_snapshots.get(dev, {})
pre_cfg_path = pre['raw']['running_config']['path'] if pre.get('raw') and pre['raw'].get('running_config') else None
post_cfg_path = post.get('raw', {}).get('running_config', {}).get('path')
cfg_diff = diff_configs(pre_cfg_path, post_cfg_path) if pre_cfg_path and post_cfg_path else ""
report['devices'][dev] = {
"pre_snapshot": pre,
"post_snapshot": post,
"config_diff": cfg_diff
}
out_path = RESULTS / run_id / "final_report.json"
out_path.parent.mkdir(parents=True, exist_ok=True)
with open(out_path, "w") as f:
json.dump(report, f, indent=2)
print(f"[+] Report written to {out_path}")
return str(out_path)
def main(testbed_file, run_id):
tb = load(testbed_file)
pre_snapshots = {}
pre_issues = {}
# 1) Pre-collection & checks
for name, device in tb.devices.items():
print(f"[{ts()}] Pre-collect {name}")
snap = collect_snapshot(device, run_id + "_pre")
pre_snapshots[name] = snap
issues = evaluate_prechecks(snap)
pre_issues[name] = issues
print("[*] Prechecks complete. Summary:")
for d, i in pre_issues.items():
print(f" {d}: {len(i)} issue(s)")
# 2) Pause & operator action (ISSU)
input(f"PAUSE: Perform ISSU now for run {run_id}. Press Enter when ISSU has started (or integrate orchestration).")
# 3) Active monitoring during ISSU
monitor_report = monitor_during_issu(tb, run_id)
print("[*] Monitoring complete. any anomalies:", len(monitor_report.get('anomalies', [])))
# 4) Post-collection & checks
post_snapshots = collect_post_checks(tb, run_id)
post_issues = {}
for name, snap in post_snapshots.items():
post_issues[name] = evaluate_prechecks(snap) # reuse baseline checks for simplicity
# 5) Report
report_path = produce_report(run_id, pre_snapshots, post_snapshots, pre_issues, post_issues, monitor_report)
print(f"[+] ISSU validation complete. Report: {report_path}")
return 0
if __name__ == "__main__":
ap = argparse.ArgumentParser()
ap.add_argument("--testbed", required=True)
ap.add_argument("--run-id", required=True)
args = ap.parse_args()
main(args.testbed, args.run_id)
Key points about this runner
- It saves raw outputs for full forensic evidence.
monitor_during_issu()is intentionally conservative — it polls logs and common protocol summaries and logs anomalies like crashes or BGP resets.evaluate_prechecks()contains the initial gating logic; you should extend it for platform-specific preflight checks (disk space, package compatibility, boot variable, compat matrices).- You can plug in a more advanced parser using Genie or vendor libraries for
show redundancyto get precise state.
Explanation by Line — deep annotated walk-through
I’ll highlight important blocks and design rationales so you (and your students) fully understand each choice.
COLLECT_CMDS
- These are minimal; customize per vendor. For NX-OS ISSU you’ll often collect:
show install all summary,show install logs,show boot,show redundancy. For IOS-XR there are different commands — vendor modules should expose correct commands.
collect_snapshot()
- Connects to the device and runs every command in
COLLECT_CMDS. - Saves raw output for each command via
save_text(). - Attempts a Genie parse for BGP as an example. If you have Genie parsers for other commands (OSPF, route), parse them for assertion logic.
evaluate_prechecks()
- Applies quick heuristics (CPU > 85%, inability to collect running-config, basic redundancy sanity).
- In production extend to:
- verify software image compatibility with ISSU (e.g.,
show versionvs vendor-provided compatibility matrix), - ensure enough free disk space (
show filesystem), - check current active/standby supervisor roles and ensure both have the same package versions or preconditions.
- verify software image compatibility with ISSU (e.g.,
monitor_during_issu()
- Polls logs and key protocol commands and stores each snapshot with a timestamp.
- Detects obvious indicators:
CRASH,CORE DUMP, BGP RESET strings — these quick checks catch severe failures. Extend with vendor-specific log patterns (e.g., NX-OS:%SYS-4-ERR).
diff_configs()
- Uses
difflib.unified_diffto produce human-friendly config differences — essential for audits & rollback decisions.
produce_report()
- Bundles everything into a single JSON report. Save
report.jsoninsideresults/<run_id>/for ingestion by dashboards.
Safety & gating
- The script pauses to let operator run ISSU or to integrate with orchestration. Never auto-run ISSU unless you have rigorous approval and staging tests.
- Use precheck results to fail fast — do not start ISSU if preflight issues exist.
testbed.yml Example
A minimal testbed — update management IPs / creds for your lab:
testbed:
name: issu_lab
credentials:
default:
username: netops
password: NetOps!23
devices:
CHASSIS_A:
os: nxos
type: switch
connections:
cli:
protocol: ssh
ip: 10.0.100.11
CHASSIS_B:
os: nxos
type: switch
connections:
cli:
protocol: ssh
ip: 10.0.100.12
EDGE1:
os: iosxe
type: router
connections:
cli:
protocol: ssh
ip: 10.0.100.21
FW1:
os: panos
type: firewall
connections:
cli:
protocol: ssh
ip: 10.0.100.31
Notes:
- For multi-tenant or VRF deployments, include
vrfcontext and extend the script to runshow ip route vrf <vrf>. - Do not commit real credentials — use environment variables or a secrets manager in production.
Post-validation CLI (Real expected output)
Below are sample realistic outputs to include in your article or slides. Use fixed-width text blocks for screenshots.
A. Pre-ISSU: show version
Chassis-A# show version Cisco NX-OS Software, version 9.3(3) System image file: bootflash:///nxos.9.3.3.bin System serial#: JAF1234ABC Supervisor: SUP1 (active)
B. Pre-ISSU: show redundancy
Chassis-A# show redundancy Redundancy mode: Stateful Switchover (SSO) Supervisor : SUP1 (Active) Supervisor : SUP2 (Standby Hot) ISSU State : Not in progress
C. Pre-ISSU: show processes cpu
CPU utilization for five seconds: 5%/2%; one minute: 6%; five minutes: 7% CPU states: 1.0% user, 0.5% system, 4.5% idle
D. During ISSU: sample monitor log (monitor snapshot)
[2025-08-28T12:17:10Z] CHASSIS_A: show logging | tail 50 %SEC-6-IPACCESSLOGP: list 101 denied tcp 198.51.100.10 %SYS-4-CPUHOG: Process xyz crashed - core dump generated
Interpretation: core dump is a red flag — immediate investigation required.
E. Post-ISSU: show ip bgp summary snippet
BGP router identifier 10.10.10.1, local AS number 65000 Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd 192.0.2.2 4 65100 10000 10002 2000 0 0 00:00:10 123
F. Sample config diff (included in report)
--- pre +++ post @@ interface mgmt0 - ip address 10.0.100.11/24 + ip address 10.0.100.11/24 ! boot nxos.9.2.2.bin +boot nxos.9.3.3.bin
G. Final report excerpt (JSON)
{
"run_id": "issu-20250828-01",
"pre_issues": {
"CHASSIS_A": [],
"CHASSIS_B": []
},
"monitor": {
"anomalies": [
{"device": "CHASSIS_A", "timestamp": "2025-08-28T12:17:10Z", "reason": "process crash in logs"}
]
},
"devices": {
"CHASSIS_A": {
"config_diff": "... unified diff ..."
}
}
}
These artifacts prove what happened, when, and provide the basis for either acceptance or rollback.
FAQs
Q1 — What preflight checks are must-have for ISSU automation?
Answer: At minimum:
- Image compatibility: ensure target image supports ISSU for that platform and chassis. Use vendor compatibility matrices.
- Redundancy state: active/standby health and sync state (SSO/NSF).
- Disk and memory: ensure enough space for package transfer / swap.
- CPU/memory headroom: no high sustained CPU or memory pressure.
- Running config backed up: snapshot saved and verified.
- No critical software bugs reported for the planned image (release notes).
Automate these preflight checks and block ISSU if any fail.
Q2 — How long should I monitor during ISSU?
Answer: It depends on platform and network size. Typical windows: 5–15 minutes for small devices, up to tens of minutes for large fabrics. The script’s MONITOR_DURATION should align with your expected ISSU time plus convergence. Also consider tracking per-prefix convergence times separately.
Q3 — My show logging shows a transient error — is that a failure?
Answer: Not necessarily. Look for severity, repeated occurrences, or process crashes (CORE DUMP, CRASH). Transient informational logs are expected. Your monitor should implement thresholds (e.g., 3 repeated errors in 2 minutes → escalate).
Q4 — How to decide rollback vs continue?
Answer: Define clear rollback criteria before ISSU:
- Critical BGP neighbors down for > X seconds.
- Y% of critical prefixes missing at the network edge.
- Core process crash detected.
If criteria met → automated rollback (if available) or manual rollback with a runbook. Your automation must produce the evidence and recommended rollback commands.
Q5 — Can pyATS trigger the ISSU procedure (image copy + install)?
Answer: Yes — but treat this as a separate, auditable process. You can integrate the ISSU orchestration (e.g., call Ansible playbook or vendor CLI command) but require multi-step approvals, preflight pass, and post-validation gating. Keep orchestration logic in a separate module and NEVER auto-upgrade in production without approvals.
Q6 — How to minimize false positives?
Answer: Correlate multiple signals (logs + process restarts + control-plane failures + data-plane test failures). Implement voting: raise an incident only if at least two independent checks fail (e.g., BGP neighbor gone + traceroute fails for critical prefix).
Q7 — What about multi-device ISSU orchestration (many chassis)?
Answer: Use canary approach: ISSU one site/pair first, validate automatically, then proceed in waves. Automate per-wave validation with this script and require success before advancing.
Q8 — Where do I store artifacts for audits?
Answer: Save results/<run_id>/ in object storage (S3/GCS) and index final_report.json into Elasticsearch. Keep raw CLI outputs and diffs for compliance and root cause postmortems.
YouTube Link
Watch the Complete Python for Network Engineer: Automating ISSU (In-Service Software Upgrade) validation Using pyATS for Cisco [Python for Network Engineer] Lab Demo & Explanation on our channel:
Join Our Training
If you want instructor-led, hands-on guidance to build robust, auditable ISSU automation — including lab exercises, CI pipelines, and dashboard integration — Trainer Sagar Dhawan is delivering a 3-month, instructor-led program covering Python, Ansible, APIs and Cisco DevNet for Network Engineers. The course walks you through exactly these masterclass patterns and helps you ship production quality automation.
Learn more & enroll: https://course.networkjourney.com/python-ansible-api-cisco-devnet-for-network-engineers/
Join the class to accelerate your path as a Python for Network Engineer — build safe, repeatable ISSU workflows that reduce outage risk and give your operations team confidence.
Enroll Now & Future‑Proof Your Career
Email: info@networkjourney.com
WhatsApp / Call: +91 97395 21088
![[Day #59 PyATS Series] Detect Split-Horizon Issues in Large Networks Using pyATS for Cisco [Python for Network Engineer]](https://networkjourney.com/wp-content/uploads/2025/08/Day-59-PyATS-Series-Detect-Split-Horizon-Issues-in-Large-Networks-Using-pyATS-for-Cisco.png)
![[Day #81 Pyats Series] Building pyATS test suites for 1000+ devices using pyATS for Cisco [Python for Network Engineer]](https://networkjourney.com/wp-content/uploads/2025/08/Building-pyATS-test-suites-for-1000-devices-using-pyATS-for-Cisco.png)
![[Day #58 PyATS Series] Validate Dynamic Routing After Topology Changes Using pyATS for Cisco [Python for Network Engineer]](https://networkjourney.com/wp-content/uploads/2025/08/Day-58-PyATS-Series-Validate-Dynamic-Routing-After-Topology-Changes-Using-pyATS-for-Cisco.png)