![Redundancy Unleashed: Keeping Enterprise Networks Always-On [CCNP Enterprise]](https://networkjourney.com/wp-content/uploads/2025/06/Redundancy-Unleashed_-Keeping-Enterprise-Networks-Always-On_networkjourney.png)
Trainer Sagar Dhawan
- Posted on
Redundancy Unleashed: Keeping Enterprise Networks Always-On [CCNP Enterprise]
I’ve seen too many organizations suffer massive outages due to a single point of failure—sometimes because of a downed switch, a failed uplink, or even a misconfigured router. In this post, I’ll walk you through the core theory, practical CLI, real-world use cases, and a hands-on EVE-NG lab so you can build your own always-on, fail-safe architecture.
Let’s master redundancy, because downtime is not an option.
Table of Contents
Theory in Brief: What Is Redundancy in Networking?
Redundancy in networking refers to providing alternate paths or components so that if one element fails, the network continues to operate seamlessly. This is a core requirement in enterprise networks, data centers, and service provider environments where uptime is crucial.
Types of Redundancy
- Link Redundancy: Multiple physical or logical links between devices.
- Device Redundancy: Dual routers, switches, or firewalls to avoid a single point of failure.
- Power Redundancy: Dual power supplies in devices connected to separate power sources.
- Path Redundancy: Traffic can take alternate routes using protocols like OSPF, EIGRP, or BGP.
Why Redundancy Matters
Without redundancy, even a minor failure can bring down an entire segment of your enterprise. Redundant designs also allow maintenance without downtime and provide resilience against hardware or link failures.
Common Redundancy Protocols
- HSRP / VRRP / GLBP – Gateway Redundancy
- STP / RSTP / MSTP – Layer 2 Loop Prevention
- EtherChannel / LACP – Link Aggregation
- OSPF / BGP / EIGRP – Dynamic Routing Path Redundancy
- VSS / StackWise / vPC – Device Redundancy
Redundancy Comparison
| Redundancy Type | Purpose | Technologies Used | Example |
|---|---|---|---|
| Link Redundancy | Prevent link failure impact | EtherChannel, LACP | Dual uplinks between switches |
| Gateway Redundancy | Prevent gateway failure | HSRP, VRRP, GLBP | Redundant router acting as default gateway |
| Device Redundancy | Ensure device failover | VSS, StackWise, vPC | Dual core switches acting as one |
| Path Redundancy | Enable dynamic failover routes | OSPF, BGP, EIGRP | Multiple links via different ISPs |
Pros and Cons
| Redundancy Type | Pros | Cons |
|---|---|---|
| Link | Simple and fast failover | Cost of additional cabling |
| Device | High availability with load sharing | Expensive hardware, more config effort |
| Gateway | Automatic failover for clients | Potential failover delays |
| Path | Intelligent routing | Complexity and convergence issues |
Essential CLI Commands
| Purpose | Command | Description |
|---|---|---|
| Check HSRP status | show standby | View HSRP group and state |
| Verify EtherChannel | show etherchannel summary | See port aggregation status |
| Check OSPF neighbors | show ip ospf neighbor | Confirm path redundancy |
| Monitor STP roles | show spanning-tree | Ensure proper L2 redundancy |
| View vPC consistency (Nexus) | show vpc consistency-parameters global | vPC config validation |
Real-World Use Case: Redundant Enterprise WAN
| Scenario | Redundancy Type | Description |
|---|---|---|
| Dual ISP for WAN connectivity | Path Redundancy | OSPF/BGP used to load balance and failover |
| StackWise Core Switches in campus | Device Redundancy | Core switch failure doesn’t impact users |
| HSRP between two routers | Gateway Redundancy | Users continue internet access even if one router fails |
| Dual fiber uplinks between access & distribution switches | Link Redundancy | Prevents downtime from cable or port failure |
EVE-NG Lab: Redundancy Topology
Lab Topology Diagram
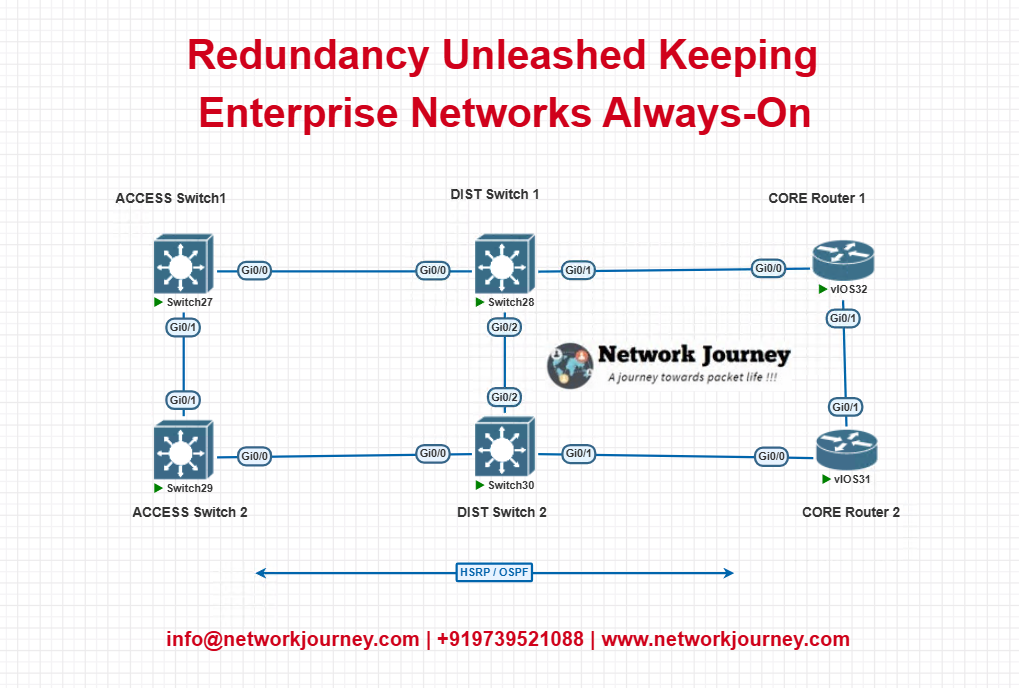
Lab Configuration
1. HSRP on Core Routers
interface g0/1 ip address 10.1.1.2 255.255.255.0 standby 1 ip 10.1.1.1 standby 1 priority 110 standby 1 preempt
2. OSPF for Path Redundancy
router ospf 1 network 10.1.1.0 0.0.0.255 area 0
3. EtherChannel on Dist-Switch
interface range g0/1 - 2 channel-group 1 mode active interface port-channel1 switchport mode trunk
Troubleshooting Tips
| Issue | Possible Cause | Resolution |
|---|---|---|
| HSRP not failing over | No preempt or same priority | Set preempt + different priorities |
| STP loops after redundancy | PortFast misused on trunk ports | Only enable PortFast on edge ports |
| EtherChannel down | Mismatched configs or speed/duplex | Use show etherchannel summary to debug |
| OSPF not forming adjacencies | Mismatched area, hello/dead timers | Check show ip ospf neighbor |
| vPC showing type-1 inconsistency | Config mismatch in VLANs or STP roles | Run show vpc consistency-parameters |
FAQs on Network Redundancy
1. What does redundancy mean in networking and why is it important?
Answer:
Redundancy in networking refers to having alternate paths, devices, or services that can take over in case of a failure. Its main goal is to maintain network uptime and eliminate single points of failure. In enterprise networks, redundancy ensures business continuity, especially for critical applications like VoIP, ERP, and cloud access.
2. What are the main types of redundancy used in enterprise networks?
Answer:
There are three major types:
- Link Redundancy: Multiple physical or logical links between devices.
- Device Redundancy: Backup switches, routers, or firewalls (e.g., dual-core switches).
- Path Redundancy: Routing protocols like OSPF, EIGRP, or BGP providing multiple routing paths.
Redundancy can also be power-based (dual PSUs), service-based (secondary ISPs), and data-based (storage replication).
3. What are the differences between Active-Active and Active-Standby redundancy?
Answer:
- Active-Active: Both devices/links are operational and share traffic load. Offers load balancing and high availability.
- Active-Standby: One device/link is active while the other is on standby. Simpler setup but less efficient resource utilization.
Each model has its use cases based on performance, cost, and complexity.
4. How does First Hop Redundancy Protocol (FHRP) fit into network redundancy?
Answer:
FHRPs like HSRP, VRRP, and GLBP allow multiple routers to present a single virtual IP address as the default gateway for end devices. If the active router fails, the standby takes over, preventing traffic disruption. GLBP even supports load balancing, unlike HSRP and VRRP which are Active-Standby by nature.
5. What role does Layer 2 redundancy play and how is it managed?
Answer:
At Layer 2, redundancy is achieved using multiple uplinks or switch paths. However, this can cause loops. Hence, protocols like Spanning Tree Protocol (STP), RSTP, and MST are used to manage redundant paths by blocking one or more to prevent loops while still providing a failover option.
6. What is the impact of redundancy on network performance and complexity?
Answer:
Redundancy improves reliability and resilience, but it can:
- Increase cost (more devices and links)
- Add configuration complexity
- Require careful design to avoid suboptimal routing or STP loops
Proper planning and use of design principles (like hierarchical models) can minimize drawbacks.
7. How can you test the effectiveness of redundancy in a live network?
Answer:
- Perform planned failover tests during maintenance windows
- Use simulation labs (EVE-NG/GNS3) before deployment
- Implement monitoring tools (like SNMP, NetFlow) to observe failover behavior
- Run ping tests, traceroutes, or disable primary links manually for testing redundancy behavior
Testing ensures that the failover mechanism works as intended.
8. What tools or protocols ensure redundancy at Layer 3?
Answer:
Key Layer 3 redundancy mechanisms include:
- Dynamic routing protocols like OSPF, EIGRP, BGP for multiple path support
- FHRPs for default gateway resilience
- BFD (Bidirectional Forwarding Detection) for fast failure detection
- Policy-based routing (PBR) to influence failover paths
These help in fast reconvergence and intelligent route selection during failures.
9. Is redundancy also applicable to WAN and Internet connectivity?
Answer:
Absolutely. WAN redundancy includes:
- Dual ISPs for internet failover
- MPLS + Broadband hybrid WAN
- SD-WAN for intelligent path selection and auto-failover
- IP SLA + Track in routers to monitor internet health and switch traffic automatically
This ensures that remote offices and cloud applications remain reachable, even if one path fails.
10. How should enterprises decide on the right level of redundancy?
Answer:
It depends on:
- Business criticality of the applications
- Downtime tolerance (RTO/RPO)
- Budget constraints
- Compliance requirements (e.g., HIPAA, PCI)
Start with a risk analysis. For critical networks, full redundancy (device, path, link) is ideal. For cost-sensitive setups, hybrid models with redundancy in core areas may suffice.
YouTube Link
Watch the Complete CCNP Enterprise: Redundancy Unleashed: Keeping Enterprise Networks Always-On Lab Demo & Explanation on our channel:
Final Note
Understanding how to differentiate and implement Redundancy Unleashed: Keeping Enterprise Networks Always-On is critical for anyone pursuing CCNP Enterprise (ENCOR) certification or working in enterprise network roles. Use this guide in your practice labs, real-world projects, and interviews to show a solid grasp of architectural planning and CLI-level configuration skills.
If you found this article helpful and want to take your skills to the next level, I invite you to join my Instructor-Led Weekend Batch for:
CCNP Enterprise to CCIE Enterprise – Covering ENCOR, ENARSI, SD-WAN, and more!
Get hands-on labs, real-world projects, and industry-grade training that strengthens your Routing & Switching foundations while preparing you for advanced certifications and job roles.
Email: info@networkjourney.com
WhatsApp / Call: +91 97395 21088
Upskill now and future-proof your networking career!
![How Can GRE Tunnel Help Connect Remote Sites? Full Cisco Setup Guide [CCNP Enterprise]](https://networkjourney.com/wp-content/uploads/2025/06/How-Can-GRE-Tunnel-Help-Connect-Remote-Sites_networkjourney.png)
![Can ARP ACLs Replace DHCP Snooping for ARP Security? Let’s Find Out! [CCNP ENTERPRISE]](https://networkjourney.com/wp-content/uploads/2025/07/nj-blog-post-ARP-ACLs.jpg)
![Mastering Ping and Traceroute: Advanced Options Every Network Engineer Should Know [CCNP Enterprise]](https://networkjourney.com/wp-content/uploads/2025/07/Mastering-Ping-and-Traceroute_Advanced-Options-Every-Network-Engineer-Should-Know_networkjourney.png)