![[Day #58 PyATS Series] Validate Dynamic Routing After Topology Changes Using pyATS for Cisco [Python for Network Engineer]](https://networkjourney.com/wp-content/uploads/2025/08/Day-58-PyATS-Series-Validate-Dynamic-Routing-After-Topology-Changes-Using-pyATS-for-Cisco.png)
Trainer Sagar Dhawan
- Posted on
[Day #58 PyATS Series] Validate Dynamic Routing After Topology Changes Using pyATS for Cisco [Python for Network Engineer]
Table of Contents
Introduction — key points
When you change topology (link shutdown, switch replacement, LAG tweak, or routing policy updates) dynamic routing protocols—OSPF and BGP—need to reconverge. A manual check (show ip route, show ip ospf neighbor, show ip bgp summary) on one device is insufficient for modern, distributed networks. You need automated, repeatable validation that:
- collects pre-change state (neighbors, routes, best-paths),
- executes or waits for the topology change (manual or automated),
- collects post-change state and measures convergence time,
- checks data-plane (traceroute/ping) and control-plane (adjacencies, route counts, next-hop changes), and
- produces audit-ready artifacts (JSON, diffs, optional dashboards).
This Article (written for the Python for Network Engineer) gives you a production-capable pyATS script, conventions for per-protocol checks, GUI ingestion notes (Elasticsearch/Kibana), and safety guidance for brownfield networks. Let’s go deep.
Topology Overview
Use a compact but realistic lab that exercises both OSPF and BGP reconvergence:
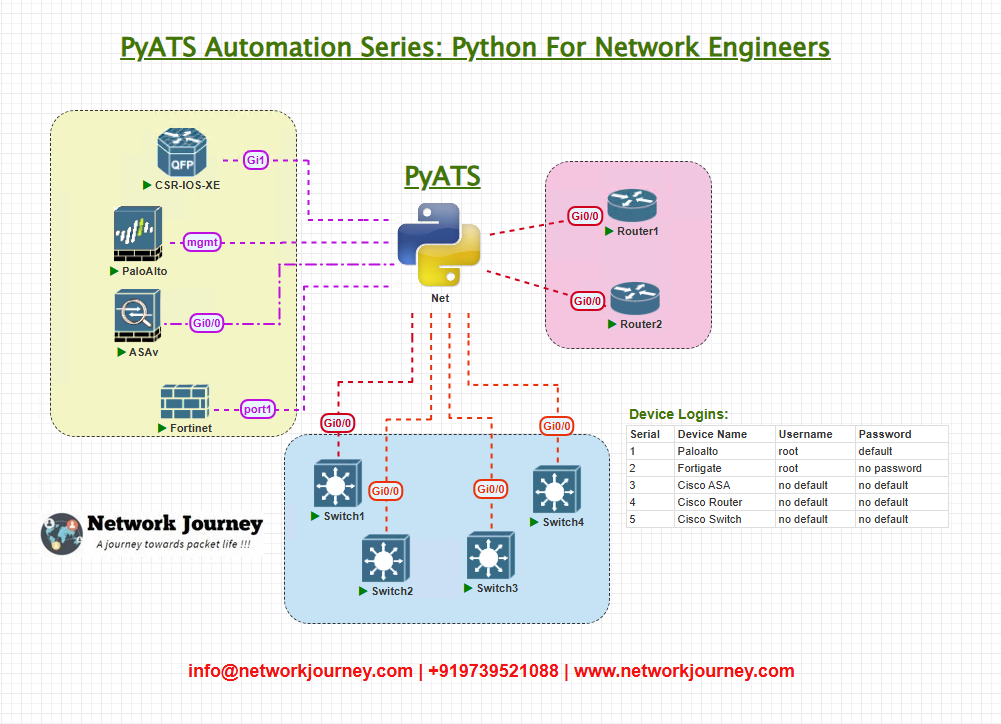
- OSPF runs inside the fabric (Dist1 ↔ Dist2 ↔ Edge routers).
- BGP runs eBGP between edge routers and external peers (simulated).
- AutomationHost (pyATS) can SSH to all devices and also run traceroutes/pings from itself or orchestrate device-sourced pings.
Devices: mix of Cisco IOS-XE and IOS-XR to demonstrate cross-platform parsing. You can substitute Arista, Junos, etc., but the patterns remain the same.
Topology & Communications
What we collect (control-plane & data-plane)
For each device we want consistent pre/post snapshots:
Control-plane:
- OSPF:
show ip ospf neighbor,show ip ospf database,show ip route ospf - BGP:
show ip bgp summary,show ip bgp neighbors <peer>,show ip bgp <prefix> - Route tables:
show ip route,show ip route <prefix> - Adjacency & interfaces:
show ip interface brief,show interfaces <intf>(counters, errors)
Data-plane:
tracerouteortrace ipfrom the automation host and device-sourced traceroutes/pings where possible. Device-sourced tests validate the local forwarding plane and ECMP behavior.
Logs / telemetry:
show loggingor syslog server ingestion — look for adjacency flaps, route withdraws, route-optimization messages (RIBchanges).- Optional telemetry (gNMI/NETCONF/Streaming) if available — push into the same validation flow.
Metrics we care about
- Adjacency status (state, uptime) per neighbor.
- Route presence for critical prefixes and whether they are active in the RIB.
- Next-hop changes (next-hop IP/interface change).
- Path changes count (number of prefix withdraws/announces).
- Convergence time — time from topology change to stable routing state (no more changes for X seconds).
- Data-plane end-to-end reachability (ping/traceroute success and path stability).
- Errors — interface errors, dropped BGP sessions, route oscillations.
Validation approach
- Baseline snapshot — collect everything above and store as
pre/<run_id>/<device>/*. - Trigger topology change — manual or via automation.
- Active convergence monitoring — poll devices every N seconds to detect when route set and adjacencies stabilize; track timestamps for events.
- Post-check snapshot — collect same artifacts and compute diffs, route delta lists, and traceroute comparisons.
- Produce report + optional push to ES — JSON + human summary.
Workflow Script — full pyATS workflow
Below is a production-style Python script for pyATS that implements the flow described. Save as dynamic_routing_validation.py. It uses Genie parsing where available and falls back to raw command parsing otherwise. It records artifacts into results/<run_id>/.
Important: This script is a mature starting point — adapt the
PREFIXES_TO_CHECK,CONVERGENCE_TIMEOUT, polling interval, and device commands for your environment. Always test in lab before running in production.
#!/usr/bin/env python3
"""
dynamic_routing_validation.py
Validate dynamic routing (OSPF/BGP) after topology changes using pyATS + Genie.
- Collect pre-change snapshots
- Optionally trigger change (placeholder)
- Monitor convergence (control-plane stable)
- Collect post-change snapshots
- Produce JSON report, diffs, convergence metrics, and traceroutes
Usage:
python dynamic_routing_validation.py --testbed testbed.yml --run-id run001
"""
import argparse, json, os, time, difflib
from datetime import datetime
from pathlib import Path
from genie.testbed import load
from pprint import pprint
RESULTS = Path("results")
RESULTS.mkdir(exist_ok=True)
# === User-configurable ===
POLL_INTERVAL = 5 # seconds between polls while waiting for convergence
CONVERGENCE_TIMEOUT = 300 # seconds to wait for stable routing after change
PREFIXES_TO_CHECK = [ # critical prefixes we expect to be present on the fabric
"10.10.0.0/16",
"192.168.100.0/24"
]
# Optional: enable Elasticsearch push (requires requests and ES reachable)
ES_PUSH = False
ES_URL = "http://localhost:9200/dynamic-routing/_doc/"
# === Helpers ===
def ts():
return datetime.utcnow().isoformat() + "Z"
def save_text(device_name, run_id, label, text):
d = RESULTS / run_id / device_name
d.mkdir(parents=True, exist_ok=True)
p = d / f"{label}.txt"
with open(p, "w") as f:
f.write(text or "")
return str(p)
def save_json(device_name, run_id, label, obj):
d = RESULTS / run_id / device_name
d.mkdir(parents=True, exist_ok=True)
p = d / f"{label}.json"
with open(p, "w") as f:
json.dump(obj, f, indent=2)
return str(p)
# === Collection functions ===
def collect_device_state(device, run_id):
"""
Collect a set of outputs from the device and return structured dict.
Uses device.parse() where available; falls back to raw device.execute().
"""
name = device.name
print(f"[{ts()}] Collecting state from {name}")
device.connect(log_stdout=False)
device.execute("terminal length 0")
state = {"device": name, "collected_at": ts(), "raw": {}, "parsed": {}}
# Commands to collect - extend per vendor as needed
cmds = {
"interfaces_brief": "show ip interface brief",
"ospf_neighbors": "show ip ospf neighbor",
"ospf_db": "show ip ospf database",
"bgp_summary": "show ip bgp summary",
"bgp_neighbors": "show ip bgp neighbors",
"ip_route": "show ip route",
}
for label, cmd in cmds.items():
try:
raw = device.execute(cmd)
state["raw"][label] = save_text(name, run_id, label, raw)
# Try Genie parse
try:
parsed = device.parse(cmd)
state["parsed"][label] = parsed
except Exception:
# keep raw only
state["parsed"][label] = None
except Exception as e:
state["raw"][label] = f"ERROR: {e}"
state["parsed"][label] = None
# For each critical prefix, capture route detail
state["routes"] = {}
for prefix in PREFIXES_TO_CHECK:
cmd = f"show ip route {prefix}"
try:
raw = device.execute(cmd)
state["routes"][prefix] = {"raw_path": save_text(name, run_id, f"route_{prefix.replace('/','_')}", raw)}
# Genie parse attempt for specific route
try:
parsed = device.parse(cmd)
state["routes"][prefix]["parsed"] = parsed
except Exception:
state["routes"][prefix]["parsed"] = None
except Exception as e:
state["routes"][prefix] = {"error": str(e)}
device.disconnect()
save_json(name, run_id, "state", state)
return state
# === Comparison & convergence ===
def extract_active_prefixes(device_state):
"""
Return a set of prefixes active in RIB based on parsed data if available, else raw parsing.
We look at 'ip_route' parsed data when possible.
"""
prefixes = set()
parsed = device_state.get("parsed", {}).get("ip_route")
if parsed:
# Genie ip route parser schema varies; attempt common access
# This is defensive and will fallback to raw search
try:
# Many Genie route parsers keep keys like 'route' or nested structure; try heuristic:
for vrf in parsed.get("vrf", {}).values() if parsed.get("vrf") else []:
# ignore VRF specifics; attempt to walk
pass
except Exception:
pass
# Fallback: parse raw ip_route file and extract network prefixes in lines
raw_path = device_state.get("raw", {}).get("ip_route")
if raw_path and os.path.exists(raw_path):
with open(raw_path) as f:
for line in f:
# lines with network/prefix often have form 'O 10.10.0.0/16 [110/2] via 10.0.1.2...'
if "/" in line and line.strip() and any(ch.isdigit() for ch in line):
# crude: split tokens and pick token with '/'
for tok in line.split():
if "/" in tok and any(c.isdigit() for c in tok):
prefixes.add(tok.strip(","))
return prefixes
def monitor_convergence(testbed, run_id, timeout=CONVERGENCE_TIMEOUT, interval=POLL_INTERVAL):
"""
Poll device route tables until the set of active prefixes stabilizes across all devices,
or until timeout. Returns a dict with per-device event timestamps and final sets.
"""
start = time.time()
last_state = {}
last_prefix_sets = {}
stable_since = None
while True:
current_prefix_sets = {}
for name, device in testbed.devices.items():
st = collect_device_state(device, run_id)
prefixes = extract_active_prefixes(st)
current_prefix_sets[name] = prefixes
# Compare with previous
if last_prefix_sets and current_prefix_sets == last_prefix_sets:
if stable_since is None:
stable_since = time.time()
# if stable for two intervals (or simply treat immediate as stable)
if time.time() - stable_since >= interval:
print(f"[{ts()}] Converged: prefix sets stable since {stable_since}")
return {"status": "converged", "prefix_sets": current_prefix_sets, "time_to_converge": time.time()-start}
else:
stable_since = None
if time.time() - start > timeout:
print(f"[{ts()}] Convergence timeout after {timeout}s")
return {"status": "timeout", "prefix_sets": current_prefix_sets, "time_elapsed": time.time()-start}
last_prefix_sets = current_prefix_sets
# small sleep
time.sleep(interval)
# === Traceroute / data-plane checks ===
def traceroute_from_host(target):
"""
Run system traceroute from automation host to target; returns text.
For more accurate tests run device-sourced traceroute via device.execute('traceroute ...').
"""
import subprocess
try:
proc = subprocess.run(["traceroute", "-n", "-w", "2", "-q", "1", target], stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True, timeout=30)
return proc.stdout
except Exception as e:
return f"ERROR: {e}"
# === Utility: do a text diff of route entries (for report) ===
def diff_states(pre_state_path, post_state_path):
try:
with open(pre_state_path) as f:
pre = f.readlines()
except:
pre = []
try:
with open(post_state_path) as f:
post = f.readlines()
except:
post = []
return "".join(difflib.unified_diff(pre, post, fromfile="pre", tofile="post"))
# === ES push ===
def push_to_es(doc):
if not ES_PUSH:
return False
import requests
try:
r = requests.post(ES_URL, json=doc, timeout=5)
r.raise_for_status()
return True
except Exception as e:
print("ES push failed:", e)
return False
# === Orchestration main ===
def main(testbed_file, run_id):
tb = load(testbed_file)
print(f"[{ts()}] Starting dynamic routing validation run {run_id}")
# 1) Pre-collection
pre = {}
for name, device in tb.devices.items():
pre[name] = collect_device_state(device, run_id + "_pre")
print(f"[{ts()}] Pre-collection complete")
# 2) Pause for operator or trigger (left as manual)
input("PAUSE: apply topology change now (or press Enter to continue after change has been made)...")
# Optionally you can call Ansible or pyATS configure here to push change
# 3) Monitor convergence actively (this will collect device states internally)
conv = monitor_convergence(tb, run_id + "_monitor", timeout=CONVERGENCE_TIMEOUT, interval=POLL_INTERVAL)
# 4) Post-collection
post = {}
for name, device in tb.devices.items():
post[name] = collect_device_state(device, run_id + "_post")
print(f"[{ts()}] Post-collection complete")
# 5) Produce diffs and report
report = {
"run_id": run_id,
"started_at": ts(),
"convergence": conv,
"devices": {}
}
for name in tb.devices.keys():
# diff ip route outputs
pre_route = pre[name]["raw"].get("ip_route")
post_route = post[name]["raw"].get("ip_route")
route_diff = ""
if pre_route and post_route:
route_diff = diff_states(pre_route, post_route)
# traceroute to prefixes from automation host
trace_results = {}
for prefix in PREFIXES_TO_CHECK:
# pick a representative IP inside prefix for traceroute: use first .1
target_ip = prefix.split("/")[0].rsplit(".",3)[0] + ".1" if "." in prefix else prefix
trace_results[prefix] = traceroute_from_host(target_ip)
# save trace
save_text(name, run_id, f"traceroute_{prefix.replace('/','_')}", trace_results[prefix])
report["devices"][name] = {
"pre_state": pre[name],
"post_state": post[name],
"route_diff": route_diff,
"traces": {p: f"results/{run_id}/{name}/traceroute_{p.replace('/','_')}.txt" for p in PREFIXES_TO_CHECK}
}
# save report
report_path = RESULTS / run_id / "report.json"
report_path.parent.mkdir(parents=True, exist_ok=True)
with open(report_path, "w") as f:
json.dump(report, f, indent=2)
print(f"[{ts()}] Report saved to {report_path}")
# optional ES push
push_to_es(report)
print(f"[{ts()}] Done.")
return report_path
if __name__ == "__main__":
ap = argparse.ArgumentParser()
ap.add_argument("--testbed", required=True)
ap.add_argument("--run-id", required=True)
args = ap.parse_args()
main(args.testbed, args.run_id)
What this script delivers:
- Pre and post raw outputs saved to
results/<run_id>/(device)/. - Active convergence monitoring that repeatedly collects state until routing tables stabilize or timeout.
- Route diffs (unified diff between
show ip routesnapshots). - Traceroutes from the Automation host to representative addresses in prefixes of interest.
- A single JSON
report.jsonbundling everything (and optional Elasticsearch push).
Explanation by Line — deep annotated walk-through
I’ll unpack the most important parts so you can adapt and harden them.
Configuration constants
POLL_INTERVAL = 5 CONVERGENCE_TIMEOUT = 300 PREFIXES_TO_CHECK = [...] ES_PUSH = False
POLL_INTERVALbalances responsiveness vs. device load. For noisy networks increase this.CONVERGENCE_TIMEOUTis how long you’ll wait for stable routing. Domain-appropriate: core convergence may be seconds; WAN may be minutes.PREFIXES_TO_CHECKshould include the most critical prefixes/services to verify (loopbacks, Internet egress blocks, DMZ networks).
collect_device_state()
- Connects to device, sets
terminal length 0, collects a set of standard commands. - Tries
device.parse(cmd)to obtain structured data via Genie — if available this gives richer detail (e.g., BGP structured dicts). - For each critical prefix runs
show ip route <prefix>to know how the device resolves it (next hop, via, administrative distance). - Saves everything (raw and parsed) and writes per-device JSON to disk — helpful for audits.
Why both raw and parsed? Raw outputs are unambiguous evidence; parsed is easier for assertions and machine checks. Keep both.
monitor_convergence()
- Polls devices (via
collect_device_state) until the set of prefixes in the RIB stabilizes across devices. - Uses
extract_active_prefixes()that attempts to parseshow ip routeparsed output; when parsing unavailable it falls back to crude raw parsing for routes that contain/. - Convergence is declared when consecutive polls produce identical prefix sets for at least one interval (
intervalseconds). Alternative robust approaches:- Detect “no changes” for N consecutive polls.
- Track specific event logs (BGP route withdraw/announce) and wait until the stream quiets.
Note: This is a high-level approach. For precise per-prefix convergence time, record timestamps of when a prefix disappears and reappears and compute per-prefix reconvergence durations.
traceroute_from_host()
- Traces from the automation host. In many cases you must run traceroute from devices to validate device-local forwarding: use
device.execute("traceroute <ip>")where possible (but be mindful of rate-limits and security).
diff_states() and report building
diff_states()uses Python’sdifflib.unified_diffto create a human-friendly diff between pre/postshow ip routesnapshots.- The final
report.jsoncontains pre/post device states, route diffs, traces paths, and theconvergencedata returned by the monitor — you can ingest this into Elasticsearch or present it in HTML.
ES push
push_to_es()is optional; production setups should enrich the report (device metadata like site, role) before indexing.
testbed.yml Example
Use this simple testbed to map devices. Don’t store production creds in plaintext.
testbed:
name: dynamic_routing_lab
credentials:
default:
username: netops
password: NetOps!23
devices:
EDGE_R1:
os: iosxe
type: router
connections:
cli:
protocol: ssh
ip: 10.0.100.11
EDGE_R2:
os: iosxr
type: router
connections:
cli:
protocol: ssh
ip: 10.0.100.12
DIST1:
os: iosxe
type: router
connections:
cli:
protocol: ssh
ip: 10.0.100.21
DIST2:
os: iosxe
type: router
connections:
cli:
protocol: ssh
ip: 10.0.100.22
Pro tips:
- Add device
customfields to includesite,role, ortagsfor richer reporting in ES/Kibana. - Use credential vaults (HashiCorp Vault, AWS Secrets Manager) in production and load credentials into testbed at runtime.
Post-validation CLI (Real expected output)
Paste these fixed-width blocks as terminal screenshots in your article to show expected pre/post evidence.
A. show ip ospf neighbor (pre-change)
R1# show ip ospf neighbor Neighbor ID Pri State Dead Time Address Interface 10.0.1.2 1 FULL/DR 00:00:34 10.0.1.2 GigabitEthernet0/0 10.0.1.3 1 FULL/BDR 00:00:38 10.0.1.3 GigabitEthernet0/1
B. show ip bgp summary (pre-change)
R1# show ip bgp summary BGP router identifier 1.1.1.1, local AS number 65000 Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd 192.0.2.2 4 65100 12345 12340 3456 0 0 2d03h 120
C. show ip route (pre-change snippet)
R1# show ip route
O 10.10.0.0/16 [110/2] via 10.0.1.2, 00:01:23, GigabitEthernet0/0
192.168.100.0/24 is directly connected, GigabitEthernet0/2
B 203.0.113.0/24 [20/0] via 192.0.2.2, 00:02:00
D. After simulated topology change (post-change) — BGP flap example
R1# show ip bgp summary Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd 192.0.2.2 4 65100 12390 12385 3458 0 0 00:00:12 118
Note: reduced prefix count shows two prefixes withdrawn during the change.
E. Sample traceroute difference (pre vs post)
Pre: traceroute to 10.10.0.1 1 10.0.1.1 <1 ms 2 10.0.1.2 <1 ms 3 10.10.0.1 <1 ms Post: traceroute to 10.10.0.1 1 10.0.1.1 <1 ms 2 10.0.1.4 10 ms 3 10.10.0.1 12 ms
Interpretation: path changed at hop 2 -> likely due to alternative path used after topology change.
F. Sample report.json snippet (reported by the script)
{
"run_id": "run001",
"convergence": {
"status": "converged",
"time_to_converge": 42.5,
"prefix_sets": {
"EDGE_R1": ["10.10.0.0/16","192.168.100.0/24","203.0.113.0/24"],
"EDGE_R2": ["10.10.0.0/16","192.168.100.0/24","203.0.113.0/24"]
}
}
}
These artifacts (raw outputs + JSON report) are what you attach to change tickets and what your monitoring/GUI will display.
Final checklist & production hardening notes
- Start small: test your script on a single site or lab slice; increase scope after stabilizing.
- Avoid destructive commands: keep this validation script read-only. If you add automated changes, separate the change runner from the validation runner and require explicit approval.
- Credential safety: use Vaults or environment variables; don’t commit secrets to testbed files.
- Telemetry first: where possible stream telemetry (gNMI/telemetry) instead of CLI polling — it’s less intrusive and more real-time.
- Observability: push
report.jsonto Elasticsearch and build dashboards for trend detection. Attachresults/<run_id>/artifacts to tickets for audits. - Unit tests: stash typical sample outputs and write small unit tests that ensure parsing logic is resilient across OS versions.
FAQs
1. How do you measure true convergence time per prefix (not just overall stability)?
Answer: Record timestamps for the first observed withdraw of a prefix (t_withdraw) and the time when the prefix reappears and is stable (t_restored). Per-prefix convergence = t_restored - t_withdraw. Implement by polling show ip route <prefix> frequently and logging state transitions. The script’s monitor_convergence() gives a coarse-grained overall convergence time; extend it to per-prefix watchers for finer metrics.
2. Why parse both control-plane and data-plane (traceroute)? Isn’t route presence enough?
Answer: Route presence in RIB shows that control-plane has accepted a path. Data-plane may still follow an old path (FIB not updated), or ECMP may forward traffic differently. Traceroutes and device-sourced pings confirm the forwarding path and reveal asymmetric paths or black-holing despite control-plane convergence.
3. What happens if devices run different OS versions with different parser availability?
Answer: Use Genie parsers where possible (they offer structured output). When not available, fall back to robust raw parsing with regex; always save raw outputs for forensic inspection. Design your script to be tolerant: it shouldn’t crash if device.parse() fails for a device — treat it as “parsed=None” and use raw outputs.
4. How do we minimize load on devices during active monitoring?
Answer: Increase POLL_INTERVAL for large fleets; poll hierarchically (collect control-plane only on core devices, more frequent at the change domain); reuse existing telemetry (gNMI/streaming) instead of polling CLI. Also schedule convergence tests during low-business windows.
5. How to handle route flapping/oscillations that never stabilize?
Answer: Protect automation with a maximum CONVERGENCE_TIMEOUT. When the timeout hits, send an alert and collect more detailed debug outputs (OSPF/BGP debug buffers, interface error counters) for human diagnosis. For persistent oscillations, integrate rate-limiting (dampening), isolation of offending devices, or policy rollback.
6. Can this be integrated into CI/CD so that a change is automatically validated?
Answer: Yes. Typical pipeline:
- Merge change to a controlled branch.
- CI triggers a change job that applies config to a canary device or limited scope.
- CI calls this pyATS validation script to run pre/post checks.
- If post-check passes (and no regressions), pipeline proceeds; if fails, fail the pipeline and optionally auto-rollback.
Make sure automation has the right safety gates and human approvals for production.
7. How do you reduce false positives caused by transient log noise?
Answer: Use noise thresholds and require repeated detection: e.g., only raise an alert if a prefix is missing for >X seconds or if the data-plane test fails N consecutive times. Correlate multiple signals — RIB missing + BGP session DOWN + traceroute fail — before escalating.
8. What extra metrics are useful to push to a dashboard for ops?
Answer: Per-run metrics for dashboards:
time_to_convergehistogram and trend line.- Number of prefixes withdrawn/added during change.
- Number of BGP/OSPF adjacencies flapping.
- Percentage of critical prefixes reachable by data-plane tests.
- Top 10 path-changed prefixes and affected sites.
Push these to Elasticsearch or Prometheus and build Kibana/Grafana panels.
YouTube Link
Watch the Complete Python for Network Engineer: Validate dynamic routing after topology changes Using pyATS for Cisco [Python for Network Engineer] Lab Demo & Explanation on our channel:
Join Our Training
If you want structured, instructor-led help building production-grade validation pipelines like this — including hands-on labs, CI/CD integration, and dashboards — Trainer Sagar Dhawan is running a 3-month instructor-led program covering Python, Ansible, APIs and Cisco DevNet for Network Engineers.
This course walks you through exactly how to turn scripts into enterprise automation, package your validation logic, and onboard it safely with your operations team. It’s the fastest way to level up as a Python for Network Engineer and own automation for your network.
Learn more & enroll:
https://course.networkjourney.com/python-ansible-api-cisco-devnet-for-network-engineers/
Join the program to make these masterclass patterns part of your team’s daily toolset — and get the hands-on guidance to deploy them safely.
Enroll Now & Future‑Proof Your Career
Email: info@networkjourney.com
WhatsApp / Call: +91 97395 21088
![Model-Driven Telemetry vs SNMP – Rethinking Network Monitoring [CCNP ENTERPRISE]_networkjourney](https://networkjourney.com/wp-content/uploads/2025/07/Model-Driven-Telemetry-vs-SNMP-–-Rethinking-Network-Monitoring-1.png)
![[Day #15 PyATS Series] Building a Reusable Test Template for All Vendors using pyATS for Cisco – Python for Network Engineer](https://networkjourney.com/wp-content/uploads/2025/07/Day15-PyATS-Series-Building-a-Reusable-Test-Template-for-All-Vendors-using-pyATS-for-Cisco-Python-for-Network-Engineer.png)
![[Day #94 PyATS Series] Validate IPv6 Neighbor Discovery Tables Using pyATS for Cisco [Python for Network Engineer]](https://networkjourney.com/wp-content/uploads/2025/09/Day-94-PyATS-Series-Validate-IPv6-Neighbor-Discovery-Tables-Using-pyATS-for-Cisco-Python-for-Network-Engineer-470x274.png)