
Sagar Dhawan
- Posted on
Ticket#2 – Server Not Reachable – Tracing Next-Hop Failure and Fix [CCNP ENTERPRISE]
Table of Contents
Problem Summary
A ticket was raised from the IT Helpdesk reporting that critical application servers hosted in the data center VLAN 130 were not reachable. Multiple users across departments couldn’t access internal services or ping the application server IP 10.130.10.10.
This seemed like a routing or Layer 3 issue, and the problem was escalated for next-hop analysis.
Symptoms Observed
- Users couldn’t ping or SSH into the application server
10.130.10.10 - DNS and AD servers on different subnets were working fine
- No STP flaps, no ARP issues observed on client access switches
- Traceroute stopped at the distribution switch IP
10.130.1.1 - Server team confirmed the application server was up with correct IP
Root Cause Analysis
Step-by-step diagnosis revealed:
- The core switch’s routing table lacked a route to the
10.130.10.0/24subnet. - OSPF was running between core and distribution, but the distribution switch had stopped advertising this subnet due to an interface shutdown.
- The next-hop interface from the distribution switch towards the server VLAN (
int vlan130) was administratively down — possibly due to a change window activity that was not reverted. - As the next-hop was unreachable, the route was withdrawn from OSPF and hence not visible in the core’s routing table.
The Fix
- Check OSPF Neighbor Status
Verified OSPF was UP between core and distribution. - Check Routing Table on Core
Usedshow ip route– route for10.130.10.0/24was missing. - Check Next-Hop Status on Distribution Switch
InterfaceVlan130was shut down. Brought it back up. - Force OSPF Refresh (if needed)
Usedclear ip ospf processorshut/no shuton OSPF interfaces to refresh LSAs. - Re-verify Route on Core
Route was reinstalled via OSPF. - Ping/SSH to Server
Verified reachability from users and NOC terminal.
EVE-NG Lab Topology
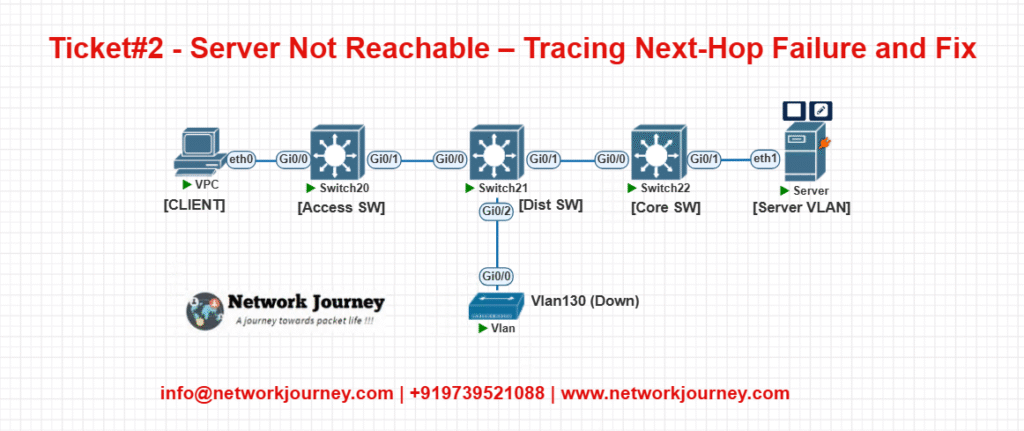
- Core runs OSPF with Dist
- Dist connects to Vlan130 (server side)
- Simulate
int vlan130shutdown and troubleshoot missing route
CLI Simulation
On Core:
show ip route 10.130.10.0
No route found
On Dist SW:
show ip ospf interface brief
show ip interface brief
Vlan130 shows status “administratively down”
Fix:
interface vlan130
no shutdown
Refresh (if needed):
clear ip ospf process
Verify on Core:
show ip route 10.130.10.0
Now visible via OSPF
Verification
| Task | Command | Expected Output |
|---|---|---|
| Check OSPF route on Core | show ip route | 10.130.10.0/24 via next-hop in Dist |
| Ping server from Core | ping 10.130.10.10 | Success |
| Ping server from client | ping 10.130.10.10 | Success |
| Interface status on Dist SW | show ip interface brief | Vlan130 is up/up |
| OSPF neighbor status | show ip ospf neighbor | FULL/DR or FULL/BDR |
Key Takeaways
- Always verify Layer 3 routing tables when destination unreachable.
- A down interface on next-hop can cause the entire route to vanish.
- OSPF dynamically withdraws routes when next-hops are unreachable.
- Use traceroute to pinpoint hop-by-hop failures.
- Document change window activities properly and monitor for rollback misses.
Best Practices & Design Tips
- Use loopback interfaces for OSPF neighbor relationships, not VLAN interfaces prone to shutdowns.
- Implement redundant routing paths to critical VLANs like server farms.
- Monitor OSPF LSAs and use SNMP traps for OSPF route changes.
- Run regular route audits using
show ip routeacross critical devices. - Use tools like NetFlow or IP SLA to catch anomalies earlier.
Real-World FAQs
1. Why didn’t OSPF advertise the server subnet?
Answer:
Because the next-hop interface (Vlan130) was down, and OSPF doesn’t advertise connected subnets with down interfaces.
2. How did we identify the failure was in next-hop?
Answer:
- Traceroute showed last reachable hop
- Core had no route for the subnet
- Distribution switch showed the next-hop VLAN down
3. Why didn’t we get alerts for this earlier?
Answer:
If interface monitoring was not configured or SNMP traps weren’t setup for Layer 3 VLANs, alerts might be missed. Fix: Monitor all routed interfaces.
4. Can we avoid this with static routing?
Answer:
Static routing wouldn’t auto-remove the route when interface is down—worse! Dynamic routing is preferred for its adaptability.
5. What’s the benefit of using loopback for OSPF neighbor adjacencies?
Answer:
Loopbacks are always up (unless device fails), so OSPF adjacency is more stable.
6. Why did users still access other services?
Answer:
Only the server subnet route was missing. Other services on other subnets continued working via their own valid routes.
7. Is OSPF passive-interface relevant here?
Answer:
Not directly. But if passive was applied mistakenly on an interface like VLAN130, it could suppress route advertisements.
8. Why did OSPF remove the route automatically?
Answer:
When a connected interface goes down, OSPF withdraws its LSA, and hence downstream routers remove that route.
9. How can we simulate such a case in EVE-NG for CCNP practice?
Answer:
- Build 3 routers (Core–Dist–Access)
- Configure OSPF between Core & Dist
- Add a loopback or SVI on Dist as the “server subnet”
- Shut the interface to simulate the issue
10. What commands help track route age in OSPF?
Answer:
show ip ospf database– to see LSA ageshow ip route– doesn’t show age but useful for path tracing
11. What’s a better way to track interface shutdowns?
Answer:
- Use
loggingfor interface status changes - Enable SNMP traps or Syslog to central monitor
- Use
archive log configto track config changes
12. Should I always clear the OSPF process after changes?
Answer:
Not always. It resets neighbor relationships. Prefer shut/no shut or wait for hello/dead timers to naturally trigger LSA updates.
YouTube Link
Final Note
Understanding how to differentiate and implement Server Not Reachable – Tracing Next-Hop Failure and Fix is critical for anyone pursuing CCNP Enterprise (ENCOR) certification or working in enterprise network roles. Use this guide in your practice labs, real-world projects, and interviews to show a solid grasp of architectural planning and CLI-level configuration skills.
If you found this article helpful and want to take your skills to the next level, I invite you to join my Instructor-Led Weekend Batch for:
CCNP Enterprise to CCIE Enterprise – Covering ENCOR, ENARSI, SD-WAN, and more!
Get hands-on labs, real-world projects, and industry-grade training that strengthens your Routing & Switching foundations while preparing you for advanced certifications and job roles.
Email: info@networkjourney.com
WhatsApp / Call: +91 97395 21088
Upskill now and future-proof your networking career!

![Mastering DHCP Snooping and Binding Table: Secure Your Layer 2 Network Like a Pro [CCNP ENTERPRISE]](https://networkjourney.com/wp-content/uploads/2025/07/nj-blog-post-dhcp-snooping-binding-table.jpg)
